การจัดการหน่วยความจำของระบบจัดการฐานข้อมูล
อัปเดท : 12 ตุลาคม พ.ศ.2546 , แสดง : 38,487 , ความคิดเห็น : 4
Application ใดๆ ก็ตามในการทำงาน จะต้องเอาข้อมูลมาใช้ได้ก็ต่อเมื่อข้อมูลอยู่ใน Memory แล้วเท่านั้น เราไม่สามารถอ่านข้อมูลจาก Disk ตรงๆ แล้วเอามาประมวลผลได้ทันที ต้อง Load ขึ้นมาอยู่ใน Memory ก่อน ดังนั้นจำเป็นต้องมีส่วนที่ทำหน้าที่จัดการตรงนี้โดยตรง ก็คือ Buffer Manager นั่นเอง
Buffer Manager
Buffer Manager รับผิดชอบเกี่ยวกับการทำ Memory Management หมายถึง จัดการเรื่องของการอ่านข้อมูลจาก Disk มาไว้ใน Memory แล้ว Load เอาข้อมูลใน Memory ออกไปลงบน Disk เพื่อจะ Clear พื้นที่ให้ว่าง สำหรับข้อมูลอื่นๆที่จะเอาเข้ามาใส่ใน Memory ได้ เนื่องจาก Memory เรามีจำนวนจำกัดเมื่อเทียบกับขนาดของ Database เราไม่สามารถเอา Database ทั้งหมดลงใน Memory ได้หมด ดังนั้น จึงต้องเลือกใช้ Memory อย่างมีประสิทธิภาพ
นอกจากนี้การ Load เอาข้อมูลจาก Memory ใส่ใน Database ก็ยังมีเงื่อนไขอย่างอื่นๆ อีกด้วย อย่างเช่น ข้อมูลบางอย่างเวลาเรา Comit Transaction ไปแล้ว หรือว่าเวลาที่เราตกลงว่า Transaction นี้มันทำงานเสร็จสิ้นสมบูรณ์ไปแล้ว เราต้องการการันตีเรื่อง ของความคงทน(Durability) ของข้อมูล เราก็ต้องบังคับให้เขียนข้อมูลนี้ ลงไปบน Disk เพราะถ้าเราไม่เขียนข้อมูลนี้ที่อยู่ใน Memory ลงไปใน Disk ถ้าระบบมันล่มขึ้นมาในตอนนั้น ข้อมูลนั้นๆก็จะหายไปจากระบบทันที แปลว่า มันจะผิดกฎเกณฑ์ของ Durability ของ Transaction ดังนั้น Memory Management ของ Database จะแตกต่างไปจาก Memory Management ของ Operating [sys]tem (OS)
ส่วนใหญ่จะเน้นเฉพาะการจัดการข้อมูลเข้ามาใน Memory , การ Clear พื้นที่ใน Memory ให้กับข้อมูลใหม่ๆ แล้วเอาข้อมูลเก่าที่คิดว่าไม่ค่อยได้ใช้แล้วลงไปสู่ใน Disk Space เหมือนเดิม แต่ว่าใน Database เราต้องเน้นทั้งในแง่ว่า ข้อมูลบางอย่างเราจำเป็นต้องเก็บใน Memory ไม่สามารถที่จะเขียนลงไปบน Disk ได้ เช่น Transaction บาง Transaction ที่มันยาวๆ มันไป แก้ไข Data บาง Data แล้วมันยังไม่ Complete พวกนั้นเราไม่ต้องการที่จะเขียนลงไปบน Disk เพราะว่า Transaction นี้ยังไม่ จบ ถ้าเราเขียน Data นี้ลงไปบน Disk แล้ว Transaction นี้เกิดล่มขึ้นมา หรือ Database เกิดล่มขึ้นมา ข้อมูลที่เรายังไม่ได้ Comit มันจะถูกบันทึกลงไปในฐานข้อมูลแล้ว มันทำให้ระบบเข้าใจว่า ข้อมูลนั้นได้รับการยอมรับแล้ว ซึ่งมันเท่ากับผิดกฎในเรื่องของ Atomicity ของข้อมูลอีกด้วย (Atomicity ของ Transaction อีกด้วย) เนื่องจากว่า ถ้า Transaction ทำงานยังไม่เสร็จสมบูรณ์ ส่วนใดๆของ Transaction ก็ห้ามไปมีผลกับ Database จนกว่าทุกๆส่วนของ Transaction จะทำงานเสร็จสมบูรณ์ ถึง [update] ผลของ Transaction นั้นลงไปในฐานข้อมูล
ดังนั้น Memory Management มันต้องระมัดระวังเรื่องข้อมูลที่ยังไม่ควรเขียนลงไปบน Disk ก็อย่าเขียน ข้อมูลที่จำเป็นต้องเขียนในทันที ก็ต้องรีบเขียนในทันที ข้อมูลไหนที่รอได้ก็ให้รอไป มันจะต่างจากใน Operating [sys]tem (OS) ที่ Flexibility ตรงนี้จะสูงกว่า เพราะว่า คุณไม่จำเป็นต้องสนใจเรื่องของ Concurrency ของข้อมูล , ไม่ต้องสนใจเรื่องของ Atomicity ข้อมูลไหนใช้แล้วโยนทิ้งได้ก็โยนทิ้งไปเลย แต่ถ้าต้องการอ่านใหม่ ก็ไปเขียนขึ้นมาใหม่ แต่ใน Database ข้อมูลบางอย่าง [update] ไปแล้ว ถูกบังคับว่าห้ามเขียนจนกว่าจะ Comit , ข้อมูลบางอย่าง Comit แล้วต้องรีบเขียนทันที เพราะว่า ถ้าไม่เขียน เดี๋ยว Database ล่มข้อมูลจะหาย อันนั้นเป็นข้อแตกต่างที่สำคัญอันหนึ่ง
ดังนั้นแล้ว Buffer Manager ของ Database มันต้องมีฟังก์ชันต่างๆที่แปลกไปจาก Buffer Manager หรือ Memory Manager ของ Operating [sys]tem (OS) ที่ยกตัวอย่างไปก็เป็น 2 อย่างด้วยกัน ก็คือเรื่องของ ข้อมูลบางอย่างของ Transaction ที่ยังไม่พร้อมที่จะ Comit ข้อมูลประเภทนั้น เรียกว่า Database หรือ Buffer Manager นี้จะทำการ Pinned block คือ Transaction ที่มาอ่านข้อมูลมันจะสั่ง Pinned block
Pinned block คือ เหมือนกับการเอาเข็มหมุดมาปักเอาข้อมูลตรงนั้นเอาไว้ให้มันติดไว้ใน Memory ไม่ให้เอาออกจาก Memory จนกว่า Transaction ที่มากระทำกับข้อมูลตัวนี้จะ Comit เมื่อ Comit แล้วก็จะเอาเข็มหมุดอันนี้ออก เหมือนกับเป็นการ Unpinned block หมายความว่า block นี้สามารถเขียนลงไปบน Disk ได้เรียบร้อยแล้ว เพราะว่า Data นี้มันถูก Comit ลงไปในฐานข้อมูลเรียบร้อยแล้ว พอข้อมูลไหนที่ถูก Unpinned มันก็อยากที่จะเขียนลงไปใน Memory ทันที เพื่อจะรับประกันว่า ถ้า Database ล่มข้อมูลนี้มันจะได้มีหลักฐานบันทึกในฐานข้อมูลเรียบร้อย ตรงส่วนนี้เรียกว่าเป็นการ Toss-immediately หมายความว่า ใน Operating [sys]tem (OS) ทั่วๆไป ข้อมูล Page ไหนก็ตามที่มันมีการอ่านอยู่ใหม่ๆ OS มันจะเก็บข้อมูลไว้ใน Memory แต่ถ้าข้อมูลบน Memory Page ไหนก็ตามที่ไม่ค่อยมีโปรแกรมใดมาอ่านมันเลย ไม่มีโปรแกรมใดมาแตะต้องมันเลย OS มันก็จะเอาข้อมูล Page นั้นลบทิ้งไปจาก Memory อาจจะเอาไปเก็บไว้บน Disk หรือ ไม่เก็บก็แล้วแต่ข้อมูลมีการ [update] หรือเปล่า แต่ว่ามันจะลบทิ้งออกจาก Memory ลักษณะนี้เราเรียกว่า Policy แบบ LRU
Buffer Replacement Policies
Least-recently used ( LRU)
หมายถึง เวลามี Memory ในคอมของคุณ ก็แบ่งเป็น blockๆ แบ่งเป็น Pageๆ แต่ว่าข้อมูลบน Disk มันมีจำนวน Page มากกว่า เพราะ Disk มันจุเยอะกว่า เวลาต้องการ Page ไหนก็ load Page นั้น ขึ้นมาใน Memory หรือว่าใช้หมดทุก Page แล้ว ทุก Page มีข้อมูลอยู่แล้ว คราวนี้ต้องการอ่านข้อมูลจาก Page นี้ขึ้นมา แล้วข้อมูล Page นี้ยังไม่อยู่ใน Memory ก็ต้องหาทาง load ขึ้นมา แต่ว่าไม่รู้ว่าจะ load ไว้ตรงไหนดี เพราะมันไมมีช่องให้ load แล้วใน Memory ก็ต้องหาทางเลือก Page ใด Page หนึ่งใน Memory เอาออก เพื่อจะเอา Page ใหม่ใส่ไปแทน เรามีวิธีการเลือก เรียกวิธีการเลือกว่าเป็น Replacement Policies เราจะต้องเลือกสัก Page หนึ่งใน Memory ออกเพื่อที่จะเอา Page ที่เราต้องการใช้ที่อยู่ใน Disk เข้ามาอยู่ใน Memory การเลือกเอา Page ไหนออก เราเรียกนโยบายของการเลือกว่า Replacement Policies ว่าจะเลือก Page ไหนออก
ใน OS จะเป็น win 95 , win 98 , unix ฯลฯ จะใช้ Replacement Policies ที่เรียกว่า LRU (Least-Recently used) หมายความว่า Page ไหนก็ตามที่ถูกใช้น้อยที่สุด ถูกใช้บ่อยน้อยที่สุด เช่น
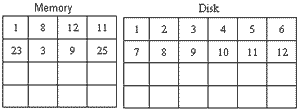
1, 8 ,12 ,11 ,23 ,3 ,9 ,25 >>> 8 ,1 ,12,3 ,9 ,23
ต่อมาใช้ Page 8 ซ้ำอีกที่หนึ่ง ใช้ Page1 Page12 Page3 Page9 ซ้ำอีกทีหนึ่ง ต่อมาต้องการใช้ Page28
Page28 ต้องหาทางว่าจะลงช่องไหนดี LRU มันก็จะมาเลือกดูว่า Page ไหนที่เก็บไว้เก่าที่สุด และยังไม่เคยถูกใช้เลย คือ Page11
ถามว่า Page ไหนที่ LRU วิธีดูก็คือ ให้ดูจาก list อันนี้ใช้ Page1 Page8 Page12 Page11 ต่อมาใช้ Page1 อีก แปลว่า Page1 เพิ่งถูกใช้ไป แสดงว่า Page1ไม่ใช่ Page ที่เก่าที่สุด ต่อมาใช้ Page 8 แปลว่า อันนี้ก็ไม่ใช่ Page ที่เก่าที่สุด ต่อมาใช้ Page12 Page3 Page9 Page23 ก็ไม่ใช่เก่าที่สุด ถามว่า Page ไหนเก่าที่สุดก็คือ Page11 คือ ตามลำดับของการใช้งาน อันนี้คือ Structure ของ LRU มันจะมี Structure แล้วบันทึกเอาไว้ว่าล่าสุดใช้ Pageไหน แล้วจะจำว่า Pageไหนที่เพิ่งใช้ใหม่ก็ลบออกจากตรงหัว แล้วไปต่อหางใหม่ Pageไหนที่อยู่ที่หัวแต่ว่าเมื่อไหร่ก็ตามที่ไม่มีที่ที่จะใส่ มันจะเอา Page ที่หัวโยนทิ้งกับเข้าไปใส่บน Disk แล้วเอา Page ใหม่ สมมติ Pageใหม่ คือ Page26 ก็ [insert] Page26 มา ต่อไป Page25 ก็จะเป็น Page ที่เรียกว่า LRU นี่คือลักษณะของ OS ทั่วๆไป การทำงานจะเป็นลักษณะอย่างนี้ คือ มันจะบันทึกเอาไว้ว่า Page ไหนมีการใช้งานตอนไหน แล้วเมื่อไหร่ที่มันไม่มีที่ว่างจะใช้แล้ว มันจะมาเลือก Page ที่ถูกแตะล่าสุดน้อยที่สุด อันนี้คือ OS
แต่ใน Database บางทีมันก็ใช้ LRU อย่างใน Oracle ก็ใช้ LRU สำหรับ Operation บาง Operation แต่ Operation บาง Operation มันจะไม่ใช้ LRU บาง Operation จะใช้ MRU (Most Recently used)
Most Recently used (MRU)
ดังนั้น มันก็จะไป scan Table มาอ่านเข้ามาใน Memory พออ่านเข้ามาใน Memory เสร็จก็รู้แล้วว่าอันนี้ไม่ได้ใช้แล้ว มันก็จะลบอันนี้ทิ้งไปเลย คือ แทนที่มันจะใช้ LRU มันไปใช้ MRU หรือการทำ Table join ก็เหมือนกัน
การทำ Table join สมมติ join Table A กับ Table B
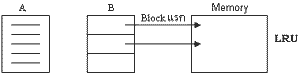
Table อยู่บน Disk เรามี Memory เวลาอ่าน record ใน Table มาใส่ใน Memory คุณอาจอ่าน Table A มาใส่ใน Memory เต็มๆเลย เสร็จแล้วก็อ่าน Table B เข้ามาใน Memory เพื่อจะมา join กับ Table A พออ่าน Table B มา(สมมติอ่าน 3-4 record แรกมาใส่ใน Memory) พออ่านมาเสร็จก็ join กับทุก record ใน Table A พอ join เสร็จ สมมติ Table B อ่านมาแค่นี้ ( blockแรก) มันเต็ม Memory แล้ว ต่อมาจะอ่าน block ถัดไปของ Table B เข้ามาแทน เพื่อจะมา join กับ A เนื่องจาก A มันถูกนำเข้ามาก่อน แล้ว Table B เพิ่งนำเข้ามาหยกๆ ถ้าใช้ LRU แปลว่า พอจะอ่าน Table B ส่วนที่ 2 ของ Table B เข้ามาใน Memory ไม่มีที่ว่างแล้วก็ต้องเอาของเก่าออก ของเก่าก็คือ เอาของ Table A ออก แล้วเอาของ Table B เข้ามาใส่แทน ปรากฎว่า พอเอาของ Table B เข้ามาใส่แทน B จะ join กับอะไร join กับ A ก็ไปอ่านเอา A เข้ามาใหม่ เพิ่งโยนทิ้งไปต้องเอาเข้ามาใหม่อีกแล้ว ดังนั้นลักษณะอันนี้มันก็ไม่ดี
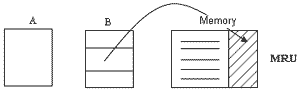
ใน Database การทำ join เป็นตัวอย่างที่ดีอันหนึ่งของ MRU ว่า ถ้าคุณมี Table A ใหญ่ขนาดนี้ และ Table B แล้วอ่าน A ทั้งหมดมาใส่ใน Memory มันเต็มขนาดนี้แล้ว(ส่วนแรกของ Memory) ต่อมา อ่าน B มาแค่นี้ (block 2) ก็เต็ม Memory (ส่วนหลัง) พอจะอ่านอีกส่วนของ B มา join กับ A คุณโยน B ของเก่าทิ้ง แล้วเอาของใหม่ B ขึ้นมาแทน อย่างนี้เรียก MRU เพราะว่า B เพิ่งจะเอาเข้ามาทีหลัง แต่โยนทิ้งออกไปก่อน เพื่อจะเอา B ถัดไปเข้ามา พอ B ถัดไปเข้ามา เสร็จแล้วก็โยนทิ้งออกไปอีก แล้วเอา B อันถัดไปเข้ามาอีก อย่างนี้เรียก MRU จริงๆแล้วอันนี้เป็น case สมมติเท่านั้น เพราะว่า จริงๆแล้ว A มันไม่สามารถ Fix ทั้ง Table ลงไปใน Memory ได้ เวลาอ่าน A จริงๆ อ่านมาแค่ส่วนหนึ่งของ A มา แล้วก็อ่านส่วนหนึ่งของ B มา แล้วก็สลับกันไปเรื่อยๆ
อันนี้เพียงแต่ต้องการจำลอง ว่า LRU ที่ใช้ใน OS ทั่วๆไป มันไม่ใช่ Policy ที่เหมาะสมกับ Database เสมอไป Database ต้องใช้หลายๆ Policy ร่วมกันขึ้นกับ Query ขึ้นกับ Operation ว่า Operation นั้นควรใช้ Policy ไหนซึ่ง DBMS โดยผ่านทาง Buffer Manager ของ DBMS จะเป็นคนเลือกเองว่าควรจะทำอย่างไร รวมถึงเรื่องตัว Concurrentcy Control Manager ด้วย มันต้องเลือกว่า Page ไหนควรจะ Pinned เอาไว้ ,Page ไหน ควรจะปล่อยออกมา , Page ไหนควรจะ Load ออกจาก Memory , Page ไหนควรจะบังคับให้อยู่ใน Memory มันเป็นเรื่องของ Replacement Policies ใน Database .... จบดีกว่า ง่วงแล้ว
ผู้เขียน/อ้างอิง : จักรกฤษณ์ แร่ทอง
เทคโนโลยีฐานข้อมูล
ใช้ MySql ผ่าน IDE บนวินโดวส์
เป็นเรื่องของ domain กับ ฐานข้อมูล
เงื่อนไขนึงที่ทำให้ระบบฐานข้อมูลมีราคาแพง
รู้จัก java กันอีกสักนิด
การติดต่อข้อมูล แบบต่าง ๆ เช่น SQL Server ,Access ,Oracle ,MySQL , Excel ,Text
ความคิดเห็น/แนะนำ/ติชม/อื่นๆ
- Pun [22 ก.ย. 2549 , 10:51 AM]
ขอบคุงมากค่ะที่เอามาแพยแพร่ ทำให้รู้การทำงานของมันเป็นยังไง แบบว่า อยากได้ การคำนวนด้วยอ่าค่ะ ^^ ขอบคุงค่ะ
- oad [02 ธ.ค. 2551 , 08:10 PM]
Thank you veru much kub
- boy [02 พ.ย. 2552 , 10:27 AM]
ดีมากเลยครัฟ
- HinZ [25 ส.ค. 2554 , 02:07 PM]
ขอบคุณมากๆ นะ ครับๆๆๆ จขกท..